
别指望算法能自动解决所有问题。尤其是当你的业务数据涉及核心机密,必须走私有化部署路线时,那种“一键清洗”的云端SaaS方案根本行不通。
本地服务器里的数据脏得千奇百怪:日期格式混乱、全角半角混用、甚至夹杂着几年前的测试乱码。这时候,单纯靠人肉改是灾难,完全交给机器又容易误杀关键信息。
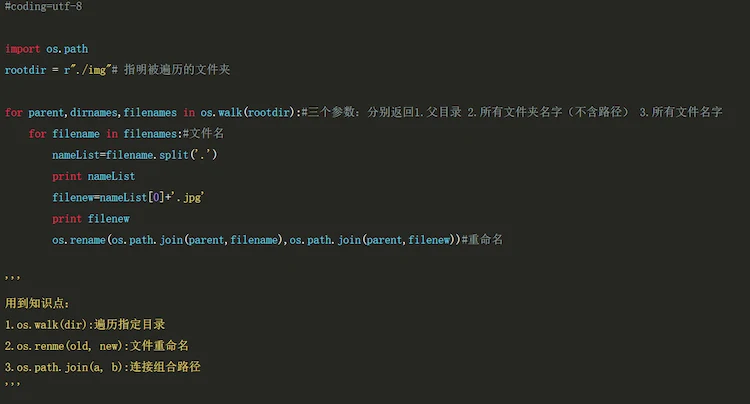
最有效的流程其实是分层处理。让脚本去干那些枯燥的体力活,比如正则匹配手机号、统一时间戳、去除首尾空格。这些规则明确、重复性高的工作,代码跑得比人快,还不会累。
但遇到语义模糊的地方,机器就歇菜了。比如客户备注里的“急单”,有的写“加急”,有的写“尽快”,还有的写“明天必到”。这种非结构化文本,AI 模型在本地部署时往往因为缺乏通用语料库的支持,判断力远不如云端大模型。

这时候就需要人介入。不是去改每一行数据,而是去定义规则边界。
我们曾在一次 CRM 系统迁移中遇到过类似情况。初始的自动化清洗脚本把大量包含特殊符号的公司名直接判定为无效数据丢弃了。损失差点发生。
后来我们调整了策略:
这种人机协作的模式,既保证了数据不出内网的安全红线,又利用了人的直觉来弥补算法的僵化。
不要试图一次性完成100%的清洗。先保证80%的高频规范数据自动化,剩下20%的长尾脏数据,通过人工审核界面快速迭代规则,才是性价比最高的做法。
在私有环境中,数据清洗本质上是一场关于效率的博弈。你不需要最聪明的 AI,你需要的是最懂业务逻辑的操作员,配合一套足够灵活的本地化工具链。
当清洗规则沉淀下来,下次再面对新批次数据时,原本需要三天的工作量,可能半小时就跑完了。这才是私有化部署该有的样子:数据留在家里,智慧长在手上。
声明:未经同意禁止任何个人或组织复制、盗用、采集、发布本站点内容到其他媒体平台。